Как составить семантическое ядро без помощи специалиста — руководство по сбору семантики для владельцев интернет-магазинов
Создать или оптимизировать контент для улучшения видимости сайта поисковой системой, изучить конкурентов и клиентов, продумать маркетинговую стратегию или рекламную компанию — все это можно сделать с помощью правильно собранного семантического ядра. На примере сбора семантического ядра для интернет-магазина, я покажу пошаговый сбор ключевых запросов, а также необходимые для этого инструменты.
- Что такое семантическое ядро?
- Структура семантического ядра.
- Сбор семантического ядра сайта пошагово.
- Фильтрация семантического ядра: стоп-слова и частотность.
- Кластеризация семантического ядра.
- Как использовать семантическое ядро.
Что такое семантическое ядро?
Семантическое ядро сайта — это набор ключевых слов и фраз наиболее релевантных тематике сайта, объединенных в отдельные группы. Важно, чтобы поисковые запросы семантического ядра максимально точно описывали содержимое сайта и его страниц, помогая поисковым системам определить, к какой нише относится сайт, какие услуги и товары он предлагает.
Семантическое ядро — важная составляющая сайта, влияющая на его дальнейшее ранжирование в поисковой выдаче. Чем точнее с помощью поисковых запросов описано содержимое страницы для поисковых систем — тем больше шансов, что она будет показана по одному из этих ключевых запросов.
Структура семантического ядра
Существует три основных правила формирования семантического ядра:
- Все ключевые запросы объединяются по кластерам (группам).
- Группа запросов содержит в себе все ключевые слова и фразы, соответствующие одной конкретной странице сайта.
- Все запросы внутри кластера должны соответствовать одному типу ключевых запросов.
Типы ключевых фраз и слов можно разделить на три основные группы:
- Навигационные. В запросе содержится название конкретного магазина или топоним.
- Информационные. Содержат вопросы (когда, почему, сколько и т.д.), а также слова вред, польза, форум, фото, видео.
- Коммерческие. Ключевые запросы со словами «купить», «цена», «интернет-магазин», точные запросы, с дополнительной информацией о товаре или услуге (модель бренд, цвет, вкус и другие характеристики).
Пример ключевых запросов
- спортивное питание розетка
- спортивное питание Украина
- спортивное питание Днепр
- когда пить протеиновый коктейль?
- почему нельзя часто есть протеиновые батончики?
- вред спортивного питания
- купить спортивное питание
- сколько стоит спортпит
- спортпит biotech usa
- спортивные добавки цена
Разные типы запросов соответствуют разным целям пользователя. Нет смысла продвигать страницу блога, рассказывающую о том, чем вредно спортивное питание по коммерческим ключам «купить спортивное питание», так как содержимое страницы не соответствует ключевому запросу. Пользователь, который хотел просто купить спортивное питание быстро покинет страницу. Такое поведение поисковая система сочтет сигналом для понижения страницы в ранжировании, поскольку она не удовлетворяет запрос пользователя.
При формировании кластера учитывается частотность ключевого запроса. Частотность ключевого слова или фразы указывает, какое количество раз запрос был введен пользователями в поисковую систему за определенный период времени.
Пример данных о частотности из сервиса Serpstat:
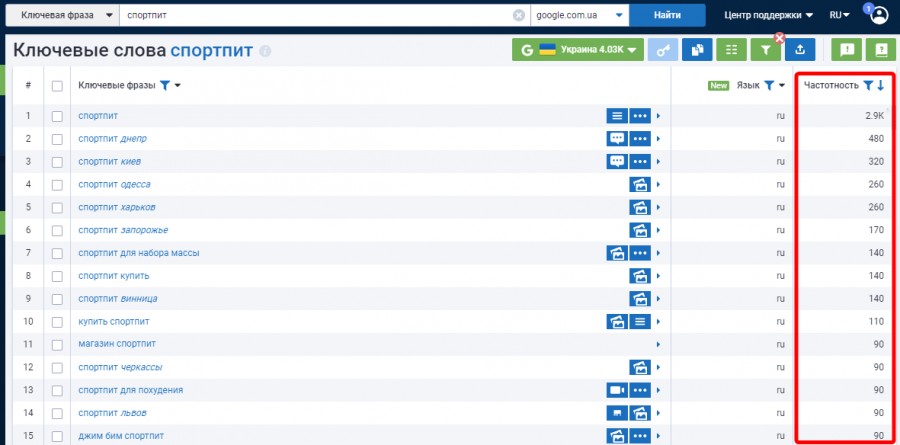
Следует выделить три типа частотности ключевых запросов:
- ВЧ (высокочастотные).
- СЧ (среднечастотные).
- НЧ (низкочастотные).
При формировании кластера семантического ядра используются все три типа частотности, кроме запросов с частотностью «0».
Визуализация структуры семантического ядра выглядит так:
Сбор семантического ядра сайта пошагово
На примере создания семантического ядра для интернет-магазина спортивного питания я покажу полный этап сбора семантики: от формирования базовых запросов до кластеризации.
Важно: Не удаляйте промежуточные результаты процесса сбора семантики. Создавайте каждый шаг на новой вкладке, чтобы всегда иметь возможность вернуться к первоначальному объему данных и иметь возможность быстро вносить изменения на любом из этапов.
Формирование базовых (маркерных) запросов
Маркерные запросы — это основные ключевые слова, широко описывающие тематику сайта. Составление списка маркерных запросов позволит вам создать скелет семантического ядра для дальнейшего сбора семантики.
Чтобы составить маркерные запросы:
1. Используйте собственный опыт и знания о продукте. Спортивное питание, которое будет представлено в интернет-магазине, можно отнести к двум популярным общеизвестным категориям: протеин и аминокислоты. После быстрого изучения ассортимента, можно выделить еще одну категорию — гейнер. На первом этапе список маркерных запросов выглядит так:
- спортивное питание;
- протеин;
- аминокислоты;
- гейнер.
2. Исследуйте нишу. Изучение темы с помощью Google-поиска поможет получить дополнительную информацию о видах и классификации продукта. Обращайте внимание на синонимы и альтернативные названия, которые используются в результатах поиска по вашим запросам.
Еще один быстрый способ углубиться в тему — использовать возможности искусственного интеллекта: (ChatGPT, Notion AI и другие). Бесплатной версии инструментов хватит, чтобы получить дополнительную информацию или сразу запросить список ключей по теме.
Пример генерации ключевых слов в Notion AI:
Обратите внимание. Несмотря на развитие и популярность AI-инструментов, ChatGPT или Notion AI все еще не являются полноценными инструментами для сбора семантического ядра, так как находятся на стадии доработки и не содержат последней актуальной информации в базе данных.
3. Изучите конкурентов. Название категорий, фильтрация — все это может стать маркерными запросами, а также помочь в создании собственной структуры сайта. Стоит учитывать, что даже если вы ориентируетесь на конкурентов, которые находятся на первых строчках поисковой выдачи, не стоит просто копировать структуру и ключевые слова с другого сайта, без предварительного анализа частотности ключевых запросов.
После изучения продукта и конкурентов, список маркерных запросов выглядит так:
- спортивное питание;
- протеин;
- аминокислоты;
- гейнер;
- спортивные добавки;
- спортпит;
- креатин;
- BCAA;
- аргинин.
Сбор семантического ядра и выбор инструментов
Собрать ключевые слова и фразы для семантического ядра можно, комбинируя следующие способы:
- анализ сайтов конкурентов;
- сбор поисковых подсказок Google по каждому из маркерных запросов;
- использование инструментов на основе искусственного интеллекта;
- использование SEO-инструментов, например, Serpstat, Semrush, Ahrefs, Keywordtool.io;
- работа с планировщиком ключевых слов Google Ads.
Собрать семантическое ядро бесплатно можно с помощью пробных версий SEO-инструментов и планировщика Google Ads. Основным минусом такого способа являются неизбежно упущенные ключевые слова.
Для сбора семантики рекомендуется использовать сразу несколько инструментов и комбинировать их в зависимости от ваших задач, например, Serpstat и Google Ads — это лучшее решение для сбора семантики на русском и украинском языках, а также поиска низкочастотных и редких запросов, которые также необходимо учитывать при сборе семантического ядра.
Обратите внимание. Точная частотность ключевых запросов будет отображена только при использовании SEO-инструментов или в планировщике ключевых слов от Google Ads (при условии, что в вашем аккаунте есть активная рекламная компания).
Сбор ключевых запросов с помощью Serpstat

- Установите регион поиска и вставьте одно из ключевых маркерных слов.
- Нажмите «Enter», Serpstat автоматически перенаправит вас в режим суммарного отчета по запрошенному ключевому слову.
- По введенному ключевому запросу в Serpstat будет доступно 7 основных SEO-отчетов.
Основной отчет по ключевому запросу
Синонимы и похожие запросы
Подсказки, предлагаемые поисковой системой Google при вводе ключевого запроса
Отчеты для изучения конкурентов
Собирая ключевые запросы для уже существующих сайтов, используйте отчет «Конкуренты». Он даст возможность просмотреть конкурентов вашей ниши в заданном регионе.
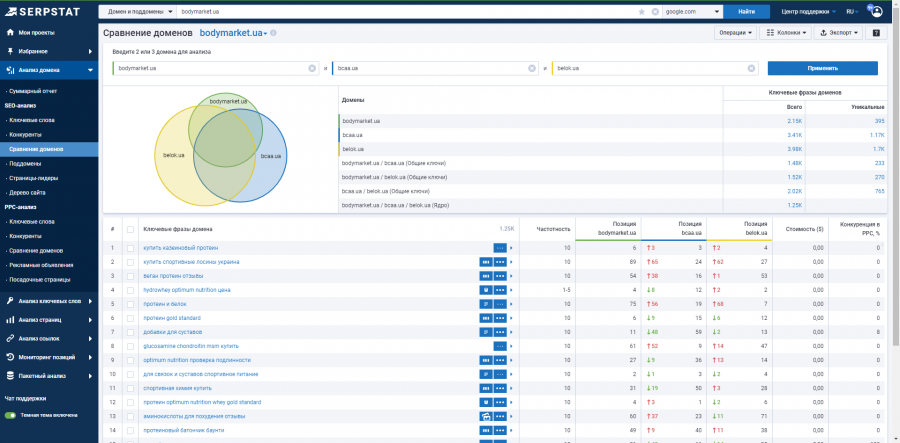
Также используйте отчет «Сравнение доменов». Введите адрес вашего сайта и двух конкурентов ниши.
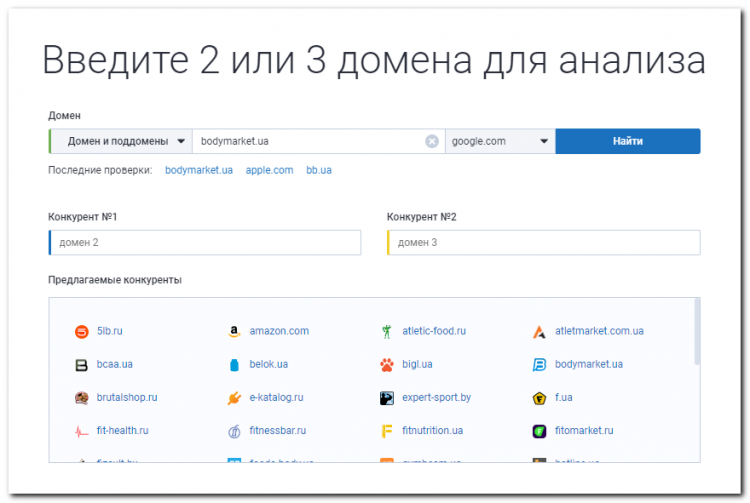
Serpstat предоставит отчеты по пересечению ключевых запросов между всеми анализируемыми доменами, а также уникальные ключевые запросы для каждого домена.
Для новых сайтов, важно использовать отчеты «Подбор фраз» и «Похожие фразы», для получения более полной семантики. Также рекомендую прорабатывать отчет «Поисковые подсказки».
Используйте фильтрацию Серпстат, чтобы уточнить поиск и отфильтровать ненужные вам запросы.

Экспортируйте отчеты в таблицы Google или другой удобный для вас формат дальнейшей работы с семантикой.
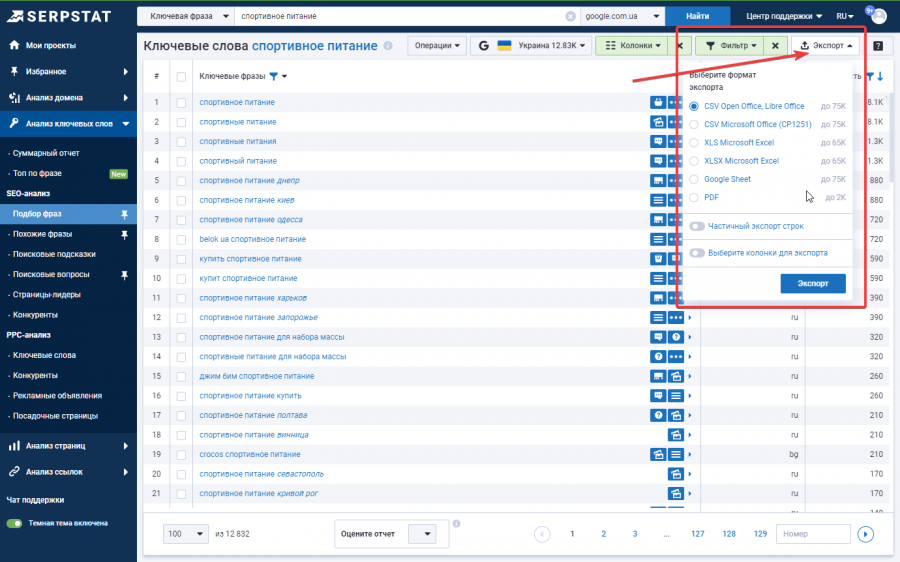
Сбор ключевых запросов с помощью Google Ads
Создайте аккаунт в Google Рекламе. С подробной инструкцией о создании аккаунта ознакомьтесь в справке Google.
-
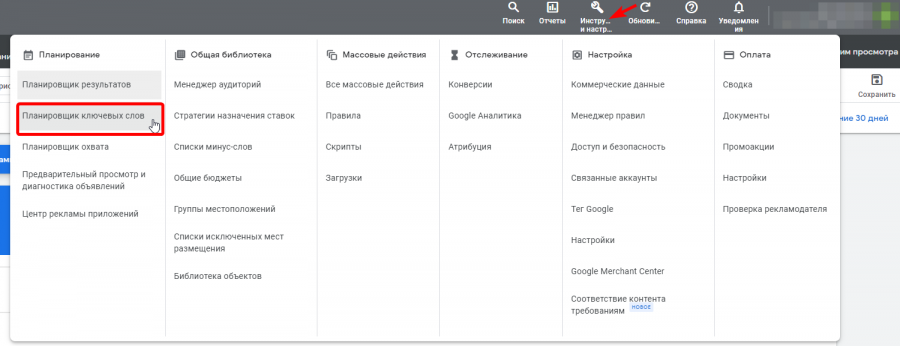
После создания аккаунта вы будете перенаправлены в ваш рекламный кабинет. Выберите в верхнем меню пункт «Инструменты и настройки», и нажмите на пункт «Планировщик ключевых слов».
Обратите внимание: Установленные региональные настройки поиска новых ключевых слов должны соответствовать региону продвижения и языку семантики.
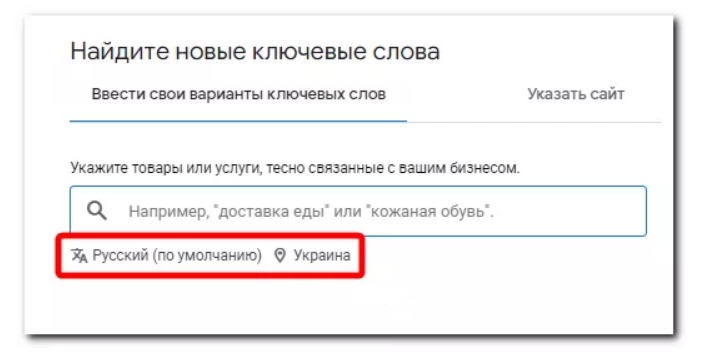
В отчете Google отобразит доступные синонимы и похожие запросы. Для расширения поиска есть дополнительные фильтры, чтобы уточнить результаты и непосредственно ключевые слова.

Если в вашем рекламном аккаунте отсутствует активная рекламная кампания, данные о частотности вы будете видеть в формате диапазона «от… до…». Если на вашем аккаунте GoogleAds запущена реклама, вы увидите точное количество запросов за месяц и график, отображающий динамику популярности запроса.

Используйте подсказки и фильтры для уточнения ключевых слов, сохраните полученные данные для дальнейшей работы с семантикой.
Формирование списка стоп-слов
Чтобы правильно распределить собранное семантическое ядро по страницам сайта, а также еще на этапе сбора удалить ненужный мусор, необходимо составить список стоп-слов.
Стоп-слова — это слова или фразы, которые характеризуют запрос или группу запросов и не релевантны вашему семантическому ядру.
Так как в примере я рассматриваю вариант коммерческого семантического ядра, то мне необходимо исключить из семантики все информационные запросы:
- что;
- почему;
- зачем;
- фото;
- видео;
- обзор;
- форум и т. д.
Обратите внимание, что вопросительные запросы могут быть смешанного типа и быть конверсионными. Например, запросы «сколько стоит», «где купить» могут отображать в результатах поиска как ссылки на интернет-магазины, так и ссылки на статьи и обзоры.
Чтобы проверить, вбейте в поиск ключевой запрос, и просмотрите первую страницу выдачи Google:
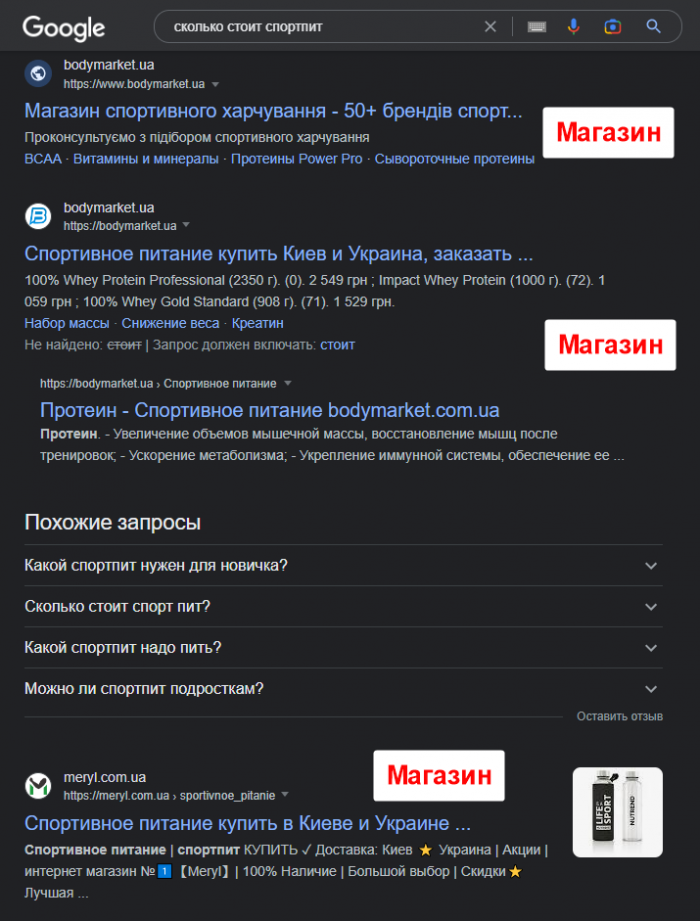
Если все ссылки на ней ведут на статьи и блоги, запрос информационный, если результаты поиска содержат интернет-магазины или смешанную выдачу, значит запрос можно отнести к коммерческим.
К универсальным стоп-словам в коммерческой семантике стоит отнести и названия магазинов конкурентов, а также регионы, в которых невозможно сделать заказ в вашем интернет-магазине.
Формирование списка стоп-слов с помощью лемматизации
Если ваш набор ключевых запросов и фраз слишком большой, для формирования более широкого списка стоп-слов, можно использовать метод лемматизации. Его суть заключается в том, чтобы унифицировать ключевые запросы: конвертировать в именительный падеж единственного числа. Это поможет найти уникальные слова, которые не относятся к формируемому семантическому ядру.
Для приведения ключевых запросов к единому виду используйте сервис Sparv 2:
- Выберете язык вашей семантики и установите следующие настройки сервиса.
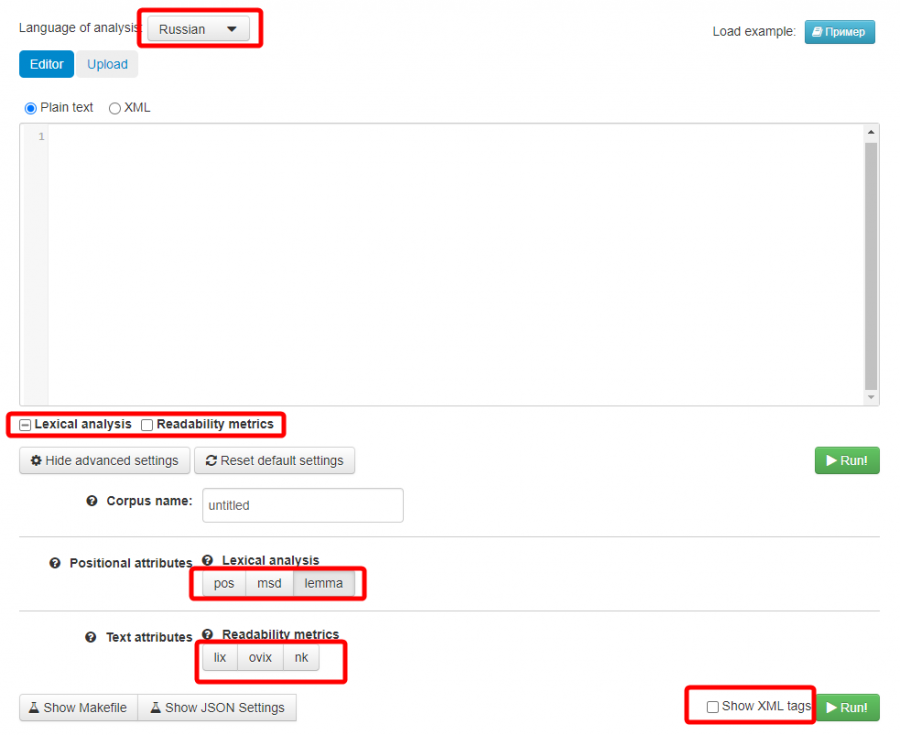
- Скопируйте или загрузите список ваших ключевых запросов в сервис Sparv 2 и нажмите кнопку «Run».
- Дождитесь выполнения задачи, внизу появится список ваших ключевых слов и лемма к ним, а также кнопка для загрузки XML-файла.
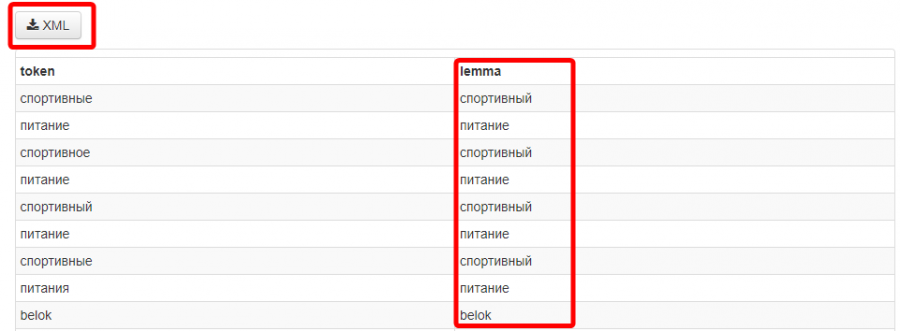
- Скачайте XML-файл и откройте с помощью стандартного блокнота или программы Notepad++.
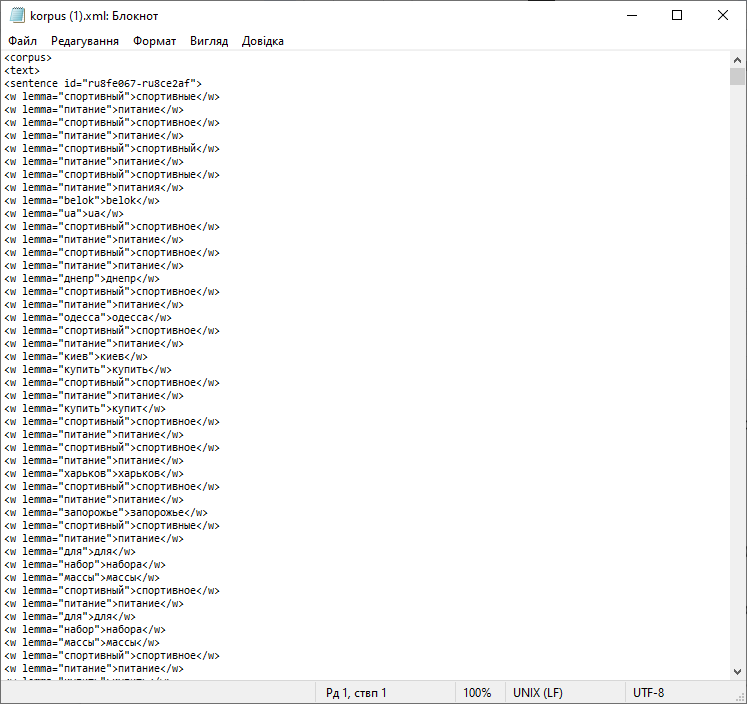
- Вставьте полученный список в Google таблицы и используйте функцию разделения текста на столбцы, с разделителем «кавычки».
- Удалите столбцы A и С и воспользуйтесь функцией очистки дублей, чтобы получить список уникальных лемм семантики.
- Изучите полученный список лемм и добавьте нерелевантные запросы в список стоп-слов.
В данном случае, запросы, которые содержат слова «орехово», «зуево» и «гиршмана» 100 % нерелевантные гео-запросы, а слово «тренировка» можно встретить как в информационных ключах («зачем нужен спортпит для тренировок»), так и в коммерческих запросах («спортпит для тренировок купить»).
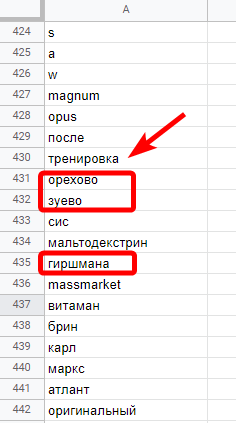
Именно поэтому при формировании стоп-слов важно сверяться с оригинальными ключевыми запросами, а также проверять поисковую выдачу по запросам, которые вызывают у вас сомнения.
Этап формирования стоп-слов — это кропотливый ручной процесс, который требует времени и терпения, но значительно облегчит последний этап создания семантического ядра — кластеризацию.
Фильтрация семантического ядра: стоп-слова и частотность
Чтобы уменьшить количество мусорных запросов в собранной семантике, перед применением списка стоп-слов, воспользуйтесь данными частотности и удалите все запросы, частотность которых равна нулю.
Для этого, актуализируйте полученные данные по частотности ключевых запросов через Serpstat или Google Ads. Важно, чтобы несмотря на то, сколько источников вы использовали для сбора семантики, показатель частотности для всех запросов был проверен через один сервис.
Актуализация в Google Ads
Перейдите в инструмент просмотра количества запросов и прогнозов.

Вы можете сразу скопировать ваши ключевые слова и фразы или загрузить их в виде CSV файла.
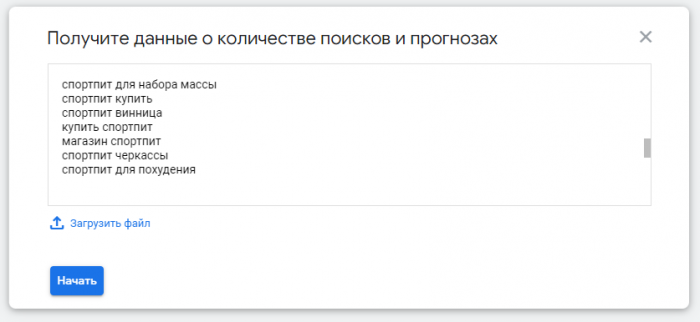
За один раз можно проверить частотность не более 20 000 запросов.
Для загрузки полученных данных выберете один из форматов в разделе «Исторические показатели плана».
Актуализация в Serpstat
Перейдите в категорию меню «Пакетный анализ» — «Пакетный анализ ключевых фраз».
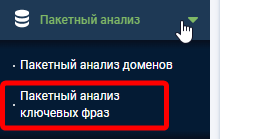
Создайте новый проект, обязательно проверьте корректность выставленного региона.
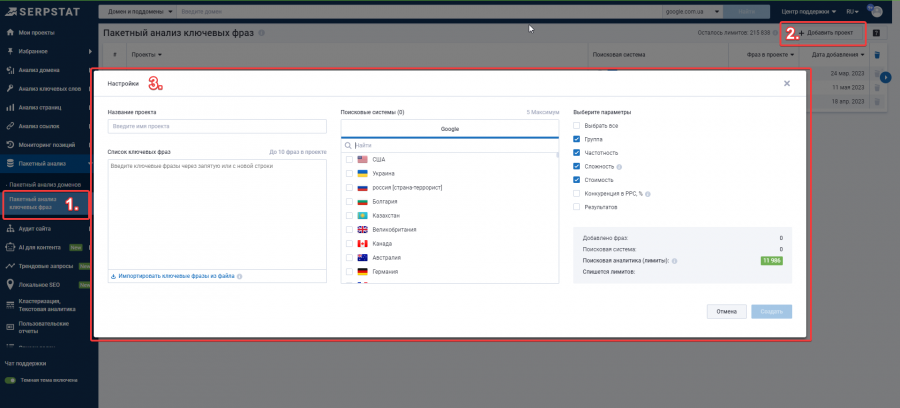
Добавьте ключевые слова и нажмите «Создать».
Используйте один из удобных для вас форматов для экспорта отчета.
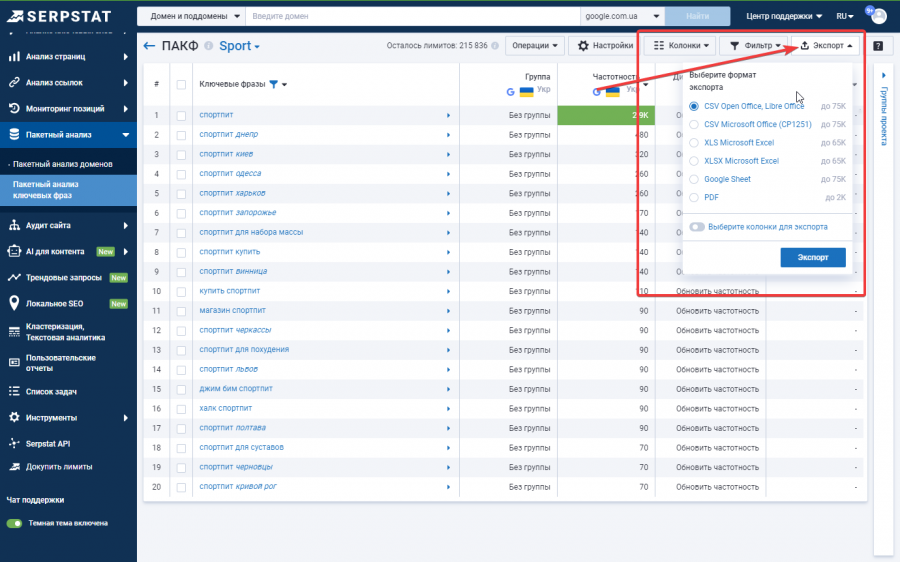
В полученном отчете Google Ads или Serpstat отфильтруйте и удалите все ключевые запросы с частотностью «0».
Теперь, полученную семантику следует очистить при помощи списка стоп-слов, который вы составляли ранее.
Для этого можно использовать специальный шаблон Google таблиц, работающий через регулярные формулы.
Скачать шаблон можно по ссылке.
- В колонку А — добавьте список ключевых запросов.
- В колонку С — добавьте список стоп-слов.
- В колонке E автоматически генерируется список ключевых запросов, которые не содержат стоп-слова.
- В колонке G отобразится список ключевых запросов, которые содержат стоп-слова.
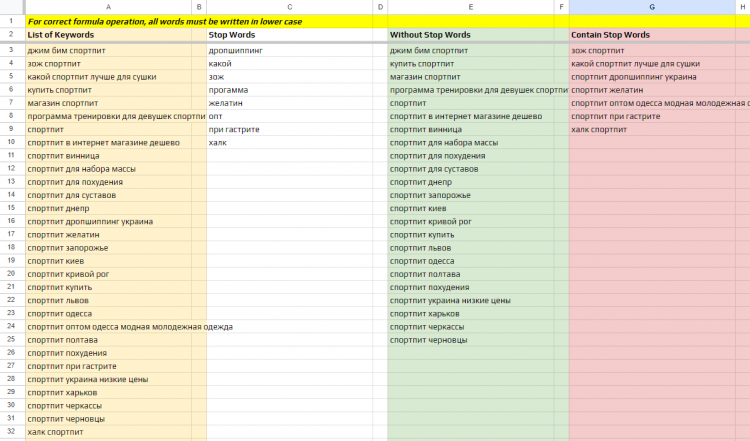
Обязательно проверьте полученные списки на наличие ошибок. Возможно, какое-то из стоп-слов оказалось некорректным и затронуло релевантные запросы.
Кластеризация семантического ядра
Для кластеризации сервисы могут использовать два вида алгоритмов:
- По результатам выдачи. Ключевые слова формируются в группы на основе того, насколько похожи результаты выдачи в поисковой системе. Такой способ кластеризации используется в Serpstat.
- По схожести фраз. Все похожие запросы попадут в одну группу, даже если результаты выдачи по ним будут сильно отличаться. Создать кластеры таким способом можно с помощью бесплатного сервиса Streamlit.app.
Лучшим способом является кластеризация семантики по результатам поисковой выдачи, так как группировка запросов по схожести может не всегда соответствовать фактическому распределению запросов пользователей.
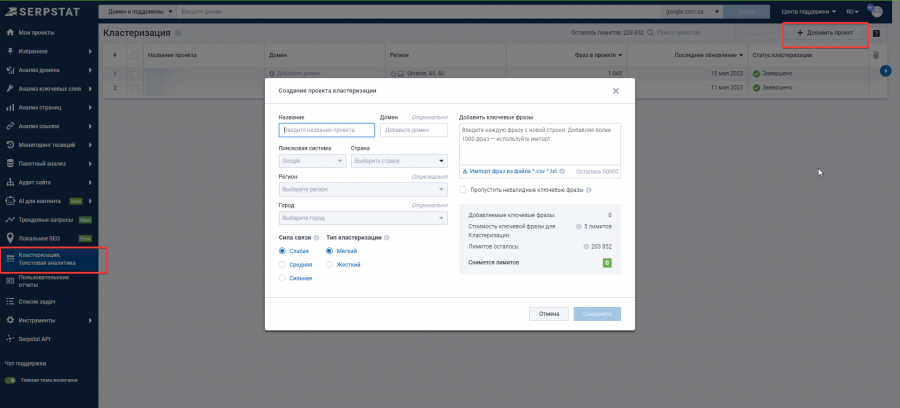
Чтобы кластеризовать ключевые слова в Serpstat:
-
Перейдите в раздел «Кластеризация» в левом боковом меню и создайте новый проект.
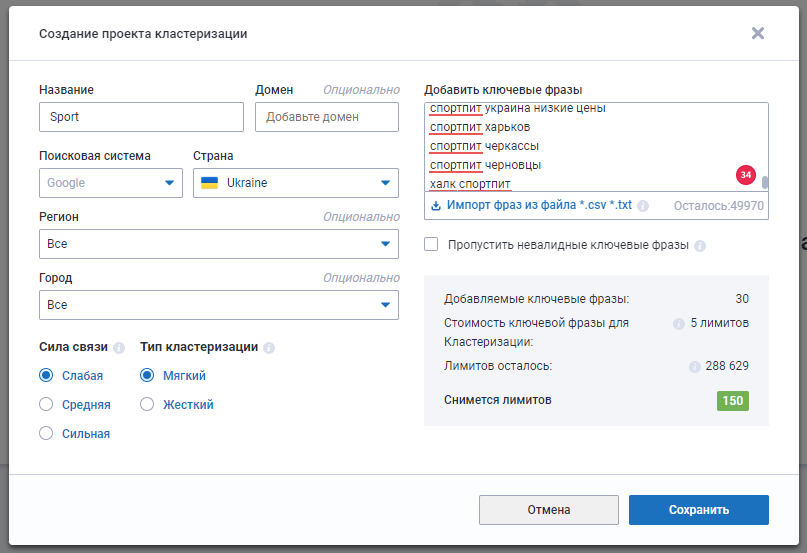
Важно: Автоматическая кластеризация не гарантирует 100 % результата.
Готовые сгруппированные в кластеры запросы распределяйте по страницам сайта, используйте для создания контента и прописывания метатегов.
Пример кластеризации ключевых запросов Serpstat:
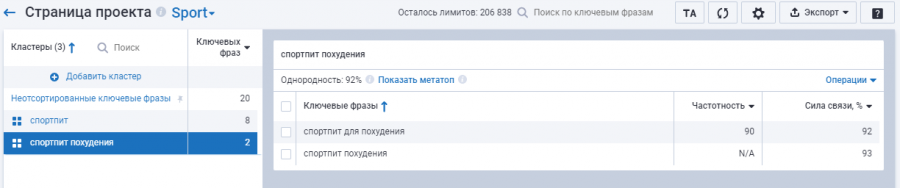
Как использовать семантическое ядро
После всех этапов очистки и кластеризации должен получиться список ключевых слов, разбитых на кластеры. Пример собранной семантики для тематики «Спортивное питание»:
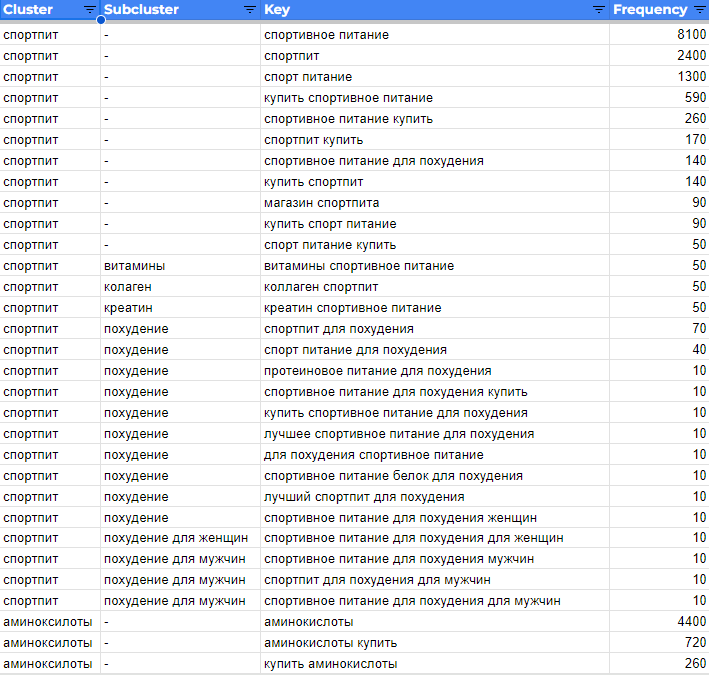
Ключевые запросы, имеющие дополнительные «хвосты», объединяются в более мелкие группы запросов (субкластеры), связанные между собой уточняющей характеристикой. Основные кластеры следует использовать для категорий и подкатегорий по типам продуктов, а субкластеры — для формирования новых посадочных страниц, фильтров.
Например, в кластере запросов «Аминокислоты» можно выделить субкалстеры по типу аминокислот (лейцин, изолейцин, валин, аргинин), по назначению (для женщин, для мужчин), по форме выпуска (порошок, таблетки, жидкие). Все эти субкластеры можно использовать для создания фильтров, которые не только помогают повысить удобство сайта, но и при оптимизации страниц фильтров приносят трафик.
Что следует запомнить?
- Правильно составленное семантическое ядро сайта и распределение ключевых запросов по страницам — один из важных факторов ранжирования.
- Не удаляйте промежуточные шаги при сборе семантического ядра. Формируйте все этапы в одном документе, но на разных вкладках. В таком случае, вы легко сможете вносить правки при необходимости.
- Для сбора семантического ядра на украинском и русском языках используйте Serpstat и Google Ads, для семантики на английском можно дополнительно использовать Ahrefs.
- Точная частотность ключа очень важна и нужна для правильного распределения ключевых запросов по страницам сайта и контенту. Для определения частотности необходимо использовать только один сервис.
- Для кластеризации лучше всего использовать инструменты, которые формируют группы запросов не по схожести фраз, а по результатам выдачи.
- Волшебной кнопки не существует. SEO-инструменты, кластеризаторы, лемматизаторы, готовые списки стоп-слов — все это лишь инструменты, которые помогают сэкономить время и сократить некоторые процессы. На каждом из этапов сбора семантического ядра основную роль играет ручная проверка и вычитка полученных результатов.
Этот текст обновлен. Первая версия вышла 15.03.2019 и её автором была Инна Вельчева.
В команде SEO Netpeak с августа 2022 года. Сейчас Junior SEO Specialist в Netpeak Agency.
Заинтересовалась SEO после посещения мероприятий и курсов от Netpeak и с того момента мечтала стать частью команды.
Узнайте больше

479
SEO-friendly HTML для верстальщика

В этой статье не будет подробного разбора всех аспектов SEO-friendly сайта. Я собрал здесь лишь тот объем информации, с которым мне необходимо было познакомиться для решения SEO-задач в компании.
В компанию ВсеИнструменты я попал больше года назад. До того момента мне еще не приходилось так тесно заниматься задачами поисковой оптимизации, а возраст и размер проекта лишь прибавляли волнения при решении seo задач. Так или иначе тот период прошел, и я не испортил своими правками уровень сайта в выдаче, благо мне помогали коллеги из SEO-подразделения.
Наш сайт, без преувеличения, состоит из огромной кодовой базы, и каждый день мы планомерно улучшаем его, добавляя новые фичи и исправляя существующие баги. Еще в начале своего пути я получил несколько крупных задач по улучшению текущей верстки проекта с использованием validator.w3.org. После окончания работ над этими задачами у меня возникла мысль собрать некоторую информацию по написанию валидной и SEO-пригодной верстки в одну небольшую статью с указанием ссылок на дополнительную и более подробную информацию.
Вы познакомитесь с несколькими важными областями валидной SEO-верстки и найдете примеры работы с validators.w3.org. Дополнительные материалы, указанные ниже, будут весьма полезны в повседневной работе верстальщика.
Семантические теги
Семантическая верстка — это html элементы со смыслом понятные разработчику, браузеру и поисковым роботам. К таким относят: header, footer, main, article, section, nav, aside и тд. Использование перечисленных тегов описывается по спецификациям W3C или WHATWG. Короткую вводную можно получить в цикле видеостатей “HTML шорты” от Вадима Макеева. Приведу описание к нескольким тегам.
Section — определяет раздел в документе. В соответствии со спецификацией W3C по HTML5: «Раздел — это тематически сгруппированный контент, как правило с заголовком.»
Article — определяет независимый, самодостаточный контент. Контент, помещенный в этот элемент, должен иметь смысл сам по себе, т. е. он должен быть понятен в отрыве от остальных частей веб-сайта.
Подробнее о article, а так же section написано здесь.
Header — предназначен для определения заголовочного блока или «шапки» документа или раздела. Подробнее здесь.
Footer — предназначен для определения «подвала» документа или раздела.
Nav — Предназначен только для основного блока навигационных ссылок.
Aside — определяет некий контент, находящийся в стороне от контента, внутри которого он расположен (как боковой блок страницы, «сайдбар»).
В целом, тема доступности сайтов довольно обширна. Со всеми нюансами предлагаю ознакомиться в этой статье и еще советую пройтись по всей серии “HTML шорты”. Еще могу посоветовать ресурс Веб стандарты, некоторые статьи писали авторы спецификации HTML5 (переводы на русский). И для понимания, можно ознакомиться с контентной моделью HTML.
Микроразметка Schema.org
Чаще всего инструкции по включению микроразметки в HTML-код вы будете получать от SEO-специалистов. Но для понимания немного осветим эту тему.
Schema.org — стандарт семантической разметки данных, который помогает поисковикам лучше понимать данные, представленные на сайте. Например, с помощью разметки можно явно указать поисковым роботам, что на странице site.ru/product_page1 находится товар, и передать основные параметры: название, цену, артикул, производителя и т.д. На основе этих данных поисковики формируют расширенные сниппеты в поисковой выдаче.
Сайты с разметкой отличаются от остальных тем, что в поисковой выдаче их сниппеты более информативны и привлекательны. Они включают в себя больше полезного контента для пользователя. Если конкурент окажется в выдаче выше, но, допустим, у него не будет микроразметки либо там будут реализованы не все фичи, наш сниппет может оказаться больше и привлекательнее. Впоследствии это может выразиться в большем количестве переходов и, соответственно, повышении поведенческих факторов, что в итоге поднимет позиции в выдаче.
Подробно о микроразметке написано в вики Яндекса. Документация Schema.org. Так же стоит обратить внимание и на гайд от Google.
Как проверить свой HTML
Так как один из критериев к SEO — это валидная верстка, необходимо прогонять написанный код через ранее упомянутый валидатор. К слову, помимо него есть валидатор от Google — в нем необходимо следить за выбранным роботом (Компьютер/Смартфон) и инструмент от Яндекса. Эти инструменты помогут Вам в задачах связанных с микроразметкой. Следует сравнивать новый и старый код, удостовериться, что ошибок нет и все существующие ранее сущности правильно считываются.
В целом, работа с ними сводится к тому, чтобы скопировать HTML код из браузера и вставить его в соответствующее текстовое поле валидатора. Можно копировать куски кода сразу из вашего IDE, но это должен быть чистый HTML с готовыми данными. После прохождения проверки вы будете получать уведомления о различных ошибках в коде. Warning можно опустить. Но от всех Error необходимо избавиться, чтобы верстка удовлетворяла принципам валидной HTML-страницы. В процессе работы могут возникнуть нерешаемые проблемы. Такое стоит гуглить и принимать во внимание, что валидаторы могут не поспевать за всеми нововведениями.
Перейдем к нескольким конкретным примерам (не)валидной верстки и их проверке с validator.w3.org.
Списки
К спискам относятся теги ul и ol (маркированные и нумерованные соответственно).
Выглядит это так:
Внутри открывающего и закрывающего тегов ul могут стоять только элементы li, а уже внутри самих этих элементов (пунктов) можно вставлять любой контент (текст, картинки, заголовки, абзацы, ссылки и даже другие списки). То есть, является не валидной версией, и https://validator.w3.org/nu/ явно об этом напишет в выводе ошибок (Рис 1).
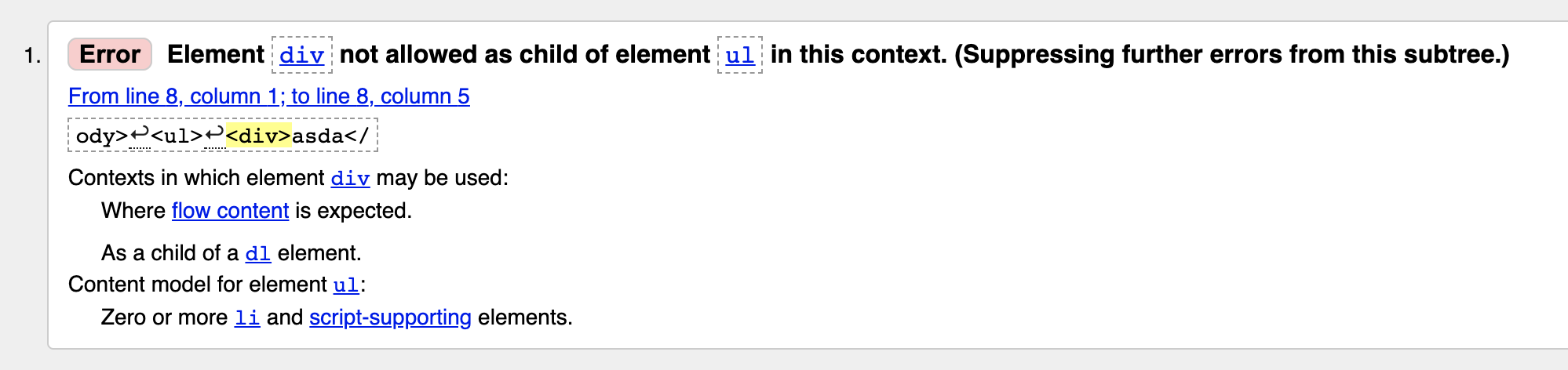
Ссылки

Атрибуты
У каждого html тега есть свой набор валидных атрибутов. Часть из них можно увидеть здесь, остальное можно найти тут.
При использовании атрибутов необходимо помнить, что существуют устаревшие.
Таблицы
Часто приходится немного корректировать базовые стили таблицы. Раньше такое реализовывалось через соответствующие атрибуты.
На данный код мы получим сразу 4 ошибки об устаревших атрибутах (Рис. 3).

Это можно спокойно переписать с использованием стилей и классов.
- border — http://htmlbook.ru/html/table/border
- cellpadding — http://htmlbook.ru/html/table/cellpadding
- cellspacing — http://htmlbook.ru/html/table/cellspacing
- width — http://htmlbook.ru/html/table/width
Резюмируя вышеописанное получим примерно такой код:
.table < border-collapse: collapse; width: 400px; border-spacing: 0; >.column
Подобное решение относится ко всем атрибутам, влияющим на стили элементов. Но есть такие, которые относятся к логике DOM-элементов. Чаще их реализация полностью падает на браузеры. Остальное можно реализовать с помощью JavaScript.
Атрибут id
Этот атрибут является неотъемлемой частью HTML. На нем часто завязаны стили и клиентский JavaScript. Данный подход уже давно не используется ввиду усложнения поддержки написанного кода. Используя id в браузере, часто можно наткнуться на проблему отсутствия уникальности значений этого свойства. Поэтому чаще всего чистый id заменяют на data-id или более специфичные названия. У нас часто используются data-атрибуты – data-behavior и data-selector. Первый подходит для взаимодействия с пользователем, второй чаще используется для манипуляций с DOM. Однако, насколько я знаю, это необязательное правило. Помимо этого, в css можно писать код с обращением в любые из свойств элементов, будь то data-* или любой другой атрибут.
Пример микроразметки
Помимо примеров валидной верстки хотелось бы привести небольшой кейс использования микроразметки Schema.org. Используя микроразметку, желательно размечать верстку, которая видна на странице и никоем образом не скрывается от пользователя при помощи opacity, visibility, display или top/left/right/bottom: -100500px. Поисковики не жалуют скрытый контент. Иногда бывают исключения, но их стоит уточнять у SEO специалистов.
Перед тем, как мы продолжим хотелось бы описать значение используемых атрибутов:
Itemscope — задает область действия словаря в структуре данных. Как правило, работает совместно с атрибутом itemtype и задаёт пределы, где itemtype будет активен. У этого атрибута нет значений.
Itemtype — указывает адрес словаря, который будет применяться для определения свойств элемента в структуре данных. Яндекс и Google поддерживают стандарт разметки Schema.org. Соответственно, в качестве значения itemtype указывается адрес словаря на этом сайте. К примеру, для разметки организаций используется значение https://schema.org/Organization.
Itemprop — используется для добавления свойств словаря микроданных к элементу. Имя свойства определяется значением itemprop, а значение свойства определяется содержимым HTML-элемента, к примеру, текстом который располагается внутри элемента.
Приведем пример микроразметки Article.
ВсеИнструменты.ру >" /> %20%3E%3E)
В данном примере представлена микроразметка статьи. Действие микроразметки ограничено дивом с атрибутами itemscope, itemtype = Article. Внутри включает микроразметку автора статьи и дату публикации. Включает в себя также краткое описание статьи и изображение. В данном кейсе при помощи бэкенда на этапе публикации парсится весь список изображений и выдается фронтенду при помощи метода getShemaOrgImageUrl().
Я не хотел бы сильно погружаться в детальные гайды по микроразметке, поэтому просто укажу несколько полезных статей на эту тему.
- Микроразметка для сайта интернет-магазина: как настроить разметку Schema.org для товаров и категорий
- Микроразметка товаров
Итог
Хотелось бы, чтобы этот материал был вам полезен. Я старался предоставить информацию для работы с SEO-версткой максимально сжато. Надеюсь, я смог достичь этой цели. Данной информации не хватит для формирования по-настоящему SEO-friendly сайта, поэтому я рекомендую использовать дополнительные материалы при разработке своих страниц. Эта тема сложна и обширна. Для плодотворного продвижения и удержания позиций сайта в поисковой выдаче необходимо работать в паре с SEO-специалистом и постоянно вести работы над улучшениями своих продуктов. Спасибо за уделенное время!
- Веб-разработка
- HTML
- Поисковая оптимизация
Источник https://netpeak.net/ru/blog/kak-sostavit-semanticheskoe-yadro-ne-obrashchayas-k-spetsialistu-rukovodstvo-dlya-vladeltsev-internet-magazinov/
Источник https://habr.com/ru/articles/538892/